
AIのエネルギー消費に関する雑感(その2)
AIの省エネ化の進め方
山本 泰生
静岡大学 情報学部 情報科学科 准教授 博士 (情報学)
さて、記事の冒頭でAI にカッコ書きで「正確には深層学習」という文言を入れたが、本来、人工知能 (Artificial Intelligence, AI) と深層学習 (Deep Learning, DL) は区別される学問対象ないし領域である。世間的に AI = DL という認識が根付いているように思われるが、人工知能学会がまとめたAIマップ (抜粋を図1に示す)[1]を見ていただくとわかるように、AI研究には知能全般に関わる幅広いテーマが含まれる。他方。近年の社会的ムーブの源泉になっているのは、あくまでニューラルネットワークを扱ったDLの歴史的成功にある。またそれと同時にエネルギー消費の問題が懸念されているのもDLである。
図1 多様なAI研究 (AIマップ[1]から抜粋)
まず、DLの内部処理についてざっと説明しておく。
DLでは、普通ネットワークとして与えられる構造 (アーキテクチャと呼ばれる) とアーキテクチャ内に組み込まれるパラメータによってモデル (入力と出力を紐づける関数のようなもの) を構築する。例えば、図2のモデルでは、左から順に入力層が2ノード (頂点)、中間層が3ノード、出力層が2ノードからなるアーキテクチャに、各辺に付されるw1,1,w1,2,…,w2,3,v1,1,…,v3,2 の各重みがパラメータとして組み込まれている。図2は全結合ネットワーク (Full Connection Network, FCN) と呼ばれるが、DLでは、FCNのような基本構造を持つ様々なモジュールを多層化したモデルが用いられる。
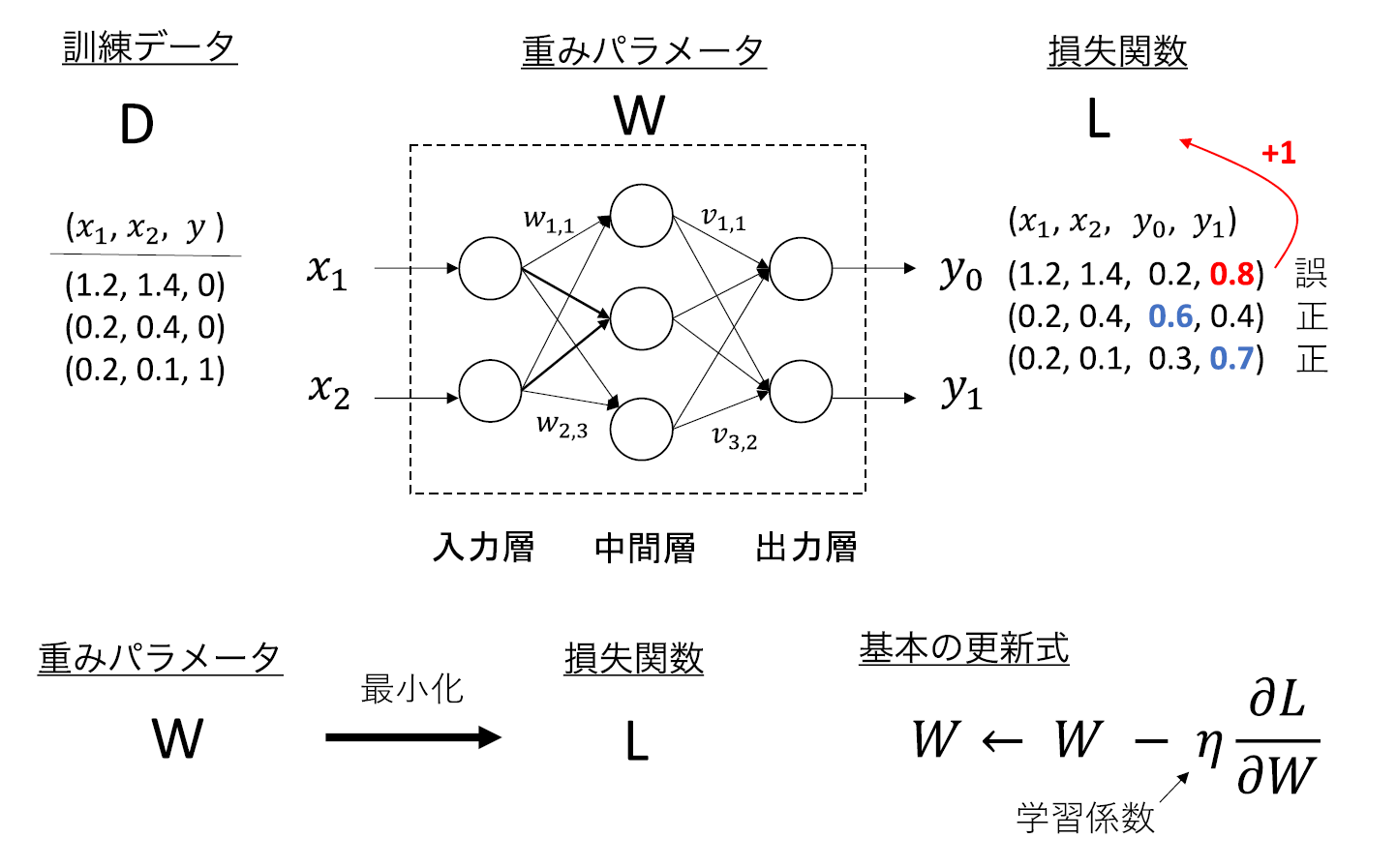
図2 全結合ネットワークモデルと重みの更新
DLモデルの計算には学習と推論の2種類がある、学習は、与えられたアーキテクチャのもと入出力の関係が最もフィットするパラメータを探索する計算処理を指す注1) 、例えば、「犬」「猫」の画像を入力したら、きちんと「犬」「猫」と出力するようなパラメータを探索する計算処理を学習と呼ぶ。一方、入力のモデル予測を求める処理を推論と呼ぶ。学習の方が大変な計算に思われるが、学習後のモデルは再利用できる。よって実際の運用では推論の方が大きなコストとなる。Nvidiaの試算ではDL処理の80-90%は推論である。
とは言っても、良いDLモデルを得るには、大量の訓練データと多数の試行錯誤を伴う学習が不可欠である。学習には一般に確率的勾配降下法 (Stochastic Gradient Descent, SGD) が利用される。DLモデルのパラメータをw、入力xに対するモデル予測を f(w;x) とし、f(w;x) と正解の出力 y との誤差を l(w;x,y) と書く。SGDでは、サンプリングされた訓練データ (x,y) に対し,l(w;x,y) が小さくなる方向にパラメータwを微小変化させていく。このような更新処理を何度も繰り返すことで望ましいパラメータを求めている。
DLモデルの大規模化に伴い学習コストも大きくなる。例えば、近年機械翻訳の精度は目覚しいものがあるが、OpenAI が2020年に発表した言語モデル GPT3 は最大1,750億個ものパラメータより構成されている。10,000基のGPU (Nvidia V100, 300W) を約2週間かけて学習しており、データセンターのPUEによるが、GPUの消費電力量だけでも1,000MWh (10,000×300W×14日×24時間) にのぼる。GPT3が学習に消費した電力量は、サンフランシスコからニューヨークに向かうジェット旅客機の3倍のCO2排出量に相当するとの試算もある[2]。
電源を切られるのが怖いと発言したとされる LaMDA[3]や初学者レベル以上のプログラミング能力を有するとされる AlphaCode[4]など現在話題となっている言語モデルはすべてGPT3と同じTransformerと呼ばれる拡張性に優れたDLモデルに基づいている。このような大規模モデルと大量の言語データをもと、計算資源を集中することで圧倒的な性能を獲得しつつあるが、反面、そのエネルギー消費は莫大なものと言える。
DLモデルのエネルギー効率を上げられないか? という問いに対して、近年様々な切り口から研究が進められている。その有力なアプローチの一つに、DLモデルのスパース性を活用するものがある。そもそも人間の脳は860億個ものニューロンで構成されているにもかかわらず、エネルギー消費はわずか20W程度 (全体の20%程度)[5]である。実は、瞬間瞬間の脳活動に関わるニューロンは全体のわずか10%程度と予測されている。興味深いことに、最近の研究でDLモデルにも脳活動と同じようなスパース性が備わっていることがわかってきている。すなわち、学習済みネットワークの中に、入力毎に定まるような部分的ネットワークが存在しており、それのみを利用しても十分精度の良い出力を推論できることが実証されている (「宝くじ仮説」と呼ばれる)。また、Google が2021年に発表した言語モデル Switch Transformer[6]では、このDLモデルのスパース性に基づく選択的学習を実装し、GPT3に比べて学習の計算コストを10分の1に削減することに成功している。さらに近年、スパース化に関するSGD収束に関する理論[7]も整備されつつあり今後の応用が期待されている。
ここまで、データセンターとAI (DL) のエネルギー消費にまつわる話題に触れてきた。Googleの報告によれば利用するDLモデル、データセンター、アクセラレータの種類によって、消費電力量に100倍から1,000倍もの違いが出ると試算されている。現在、環境、医療、食糧といった諸問題へのAI活用が進んでいるが、それと同時にAI自身を省エネ化することも求められる。と言うものの、EVのようにAIの電力消費に国民的な関心が向けられる時代が本当に来るかどうか? 賢明な読者諸兄の判断に委ねたい。
- 注1)
- アーキテクチャ自体を探索する問題やソリューションもある (例. AutoML)
【参考文献】
- [1]
- 人工知能学会: AIマップ 2020年6月11日版
https://www.ai-gakkai.or.jp/resource/aimap/ - [2]
- D. Patterson et al.: Carbon emissions and large neural network training, arXiv
https://arxiv.org/abs/2104.10350 - [3]
- B. Curtis et al.: Is Google’s LaMDA conscious? A philosopher’s view, the conversation, June 15, 2022
https://theconversation.com/is-googles-lamda-conscious-a-philosophers-view-184987 - [4]
- Y. Li et al.: Competition-level code generation with AlphaCode, arXiv
https://arxiv.org/abs/2203.07814 - [5]
- T. Hoefler et al.: Sparsity in deep learning: pruning and growth for efficient inference and training in neural networks, Journal of Machine Learning Research
https://www.jmlr.org/papers/volume22/21-0366/21-0366.pdf - [6]
- W. Fedus et al.: Switch transformers: scaling to trillion parameter models with simple and efficient sparsity, Journal of Machine Learning Research
https://www.jmlr.org/papers/volume23/21-0998/21-0998.pdf - [7]
- S. U. Stich et al.: Sparsified SGD with memory, NeurIPS 2018
https://proceedings.neurips.cc/paper/2018/file/b440509a0106086a67bc2ea9df0a1dab-Paper.pdf















